
Kontextuelle Informatik

Die Fachgruppe Kontextuelle Informatik unterstützt im Projekt den Forschungsdiskurs von Kunst- und Wirtschaftshistorikern durch die Entwicklung einer webbasierten Arbeitsumgebung. Die Herausforderung ist dabei, den Eingabeprozess in die zu entwickelnde historische Datenbank so früh wie möglich zu unterstützen und dabei semantische Zusammenhänge und darauf aufbauende Suchanfragen flexibel zu ermöglichen. Das entwickelte formale Datenbankschema soll Objektrelationen ohne einschränkende Festlegung erlauben, jedoch nicht erzwingen.
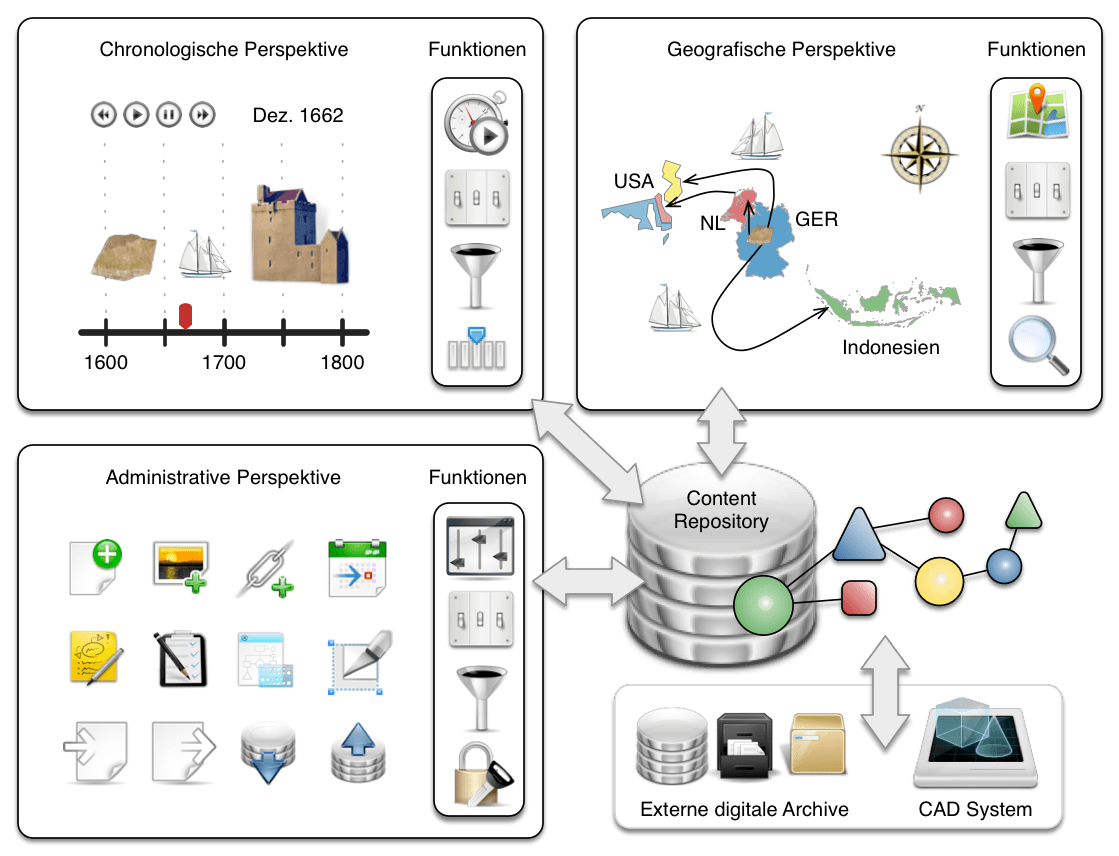
An die Aufbereitung der unterschiedlichen Quellen mit ihren verschiedenen Ausgangsformaten und Repräsentation schließt sich nach entsprechender Ablage in der Datenbank die weitergehende Analyse und ein entsprechender Forschungsdiskurs an. Das System ermöglicht dabei eine hermeneutische Feinarbeit im Sinne eines „Close Reading“, die nach Möglichkeit zu einem entsprechenden Erkenntnisgewinn führt, der sich allein durch strukturierte Dateneingabe und bloße Volltextsuche nicht realisieren ließe. Abschließend sollen die gewonnenen Forschungsergebnisse aufbereitet und visualisiert werden, um sie der interessierten Öffentlichkeit online präsentieren zu können.
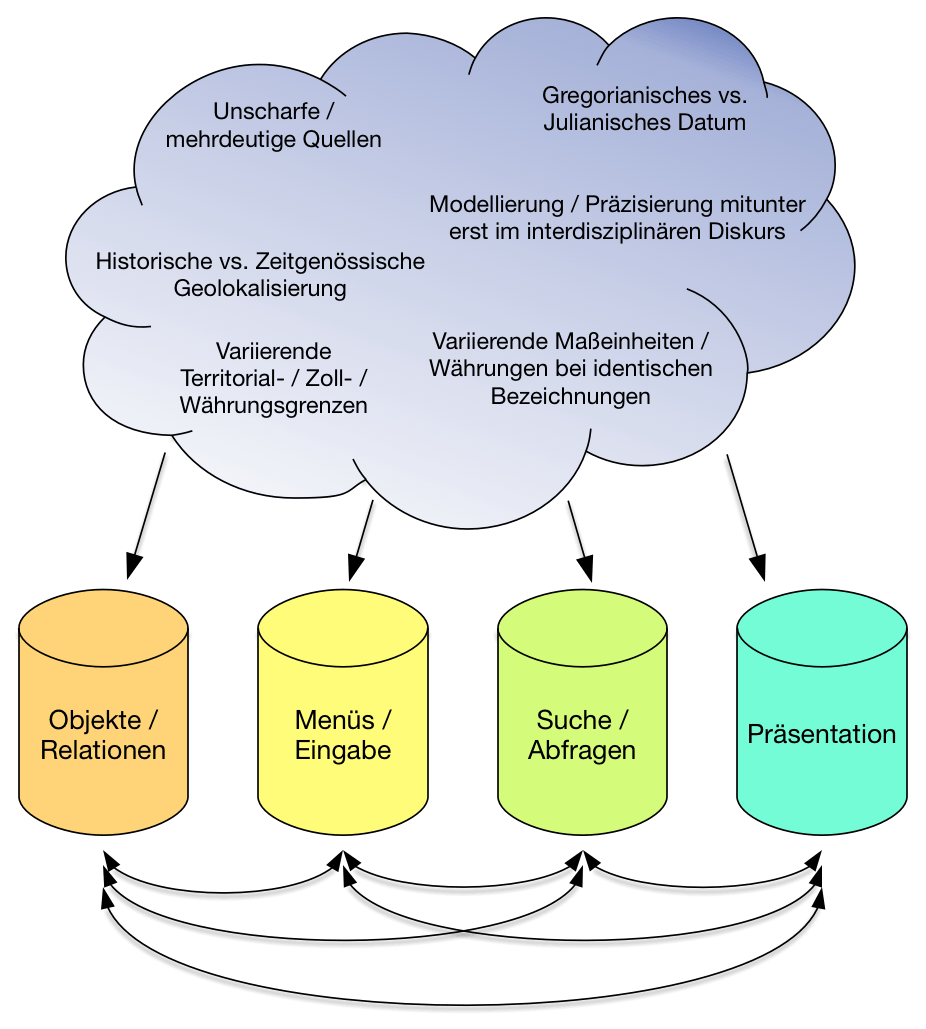
Die anfänglich vollzogene klassisch-informatische Herangehensweise mit Fokus auf dem Arbeitsgegenstand, nämlich die Implementation einer von Grund auf projektspezifischen Datenbank basierend auf einer anfänglich analytisch ermittelten Objekthierarchie, erwies sich als wenig geeignet: Weniger offensichtliche Strukturen und semantische Zusammenhänge entfalteten sich teilweise erst im Laufe der Projektlaufzeit im interdisziplinären Forschungsdiskurs und zwangen zu immer neuen Umbauten am Objektmodell. Dem geschuldet erfolgte ein Perspektivenwechsel, wodurch nunmehr der Arbeitsprozess in den Vordergrund rückte: Die Datenbank wurde auf einer zunächst generischen Objektstruktur realisiert, während spezifische Objekt-Eigenschaften und Bezüge zwischen unterschiedlichen Objekttypen erst nachträglich erweitert wurden.
Zur Umsetzung dieses Ansatzes fiel die Wahl auf die im kulturwissenschaftlichen Umfeld bewährte Open Source Software-Plattform Omeka. Dessen spezifische Eigenschaften unterscheiden sich deutlich von denen eines gewöhnlichen, webbasierten Content Management Systems: Neben der Möglichkeit zur Präsentation der eingepflegten Inhalte in einem öffentlichen Web-Frontend gestattet Omeka vor allem die strukturierte Speicherung von verschiedensten, immanent generischen Objekttypen und deren Verknüpfung untereinander, mitsamt Werkzeugen zur tiefergehenden semantischen Analyse des Datenbestandes sowie der anschließenden Online-Präsentation der Ergebnisse.
Auf der Basis mitunter unscharfer oder sogar widersprüchlicher Quellen und gleichermaßen offener Bezüge wurde im interdisziplinären Dialog zwischen Kulturwissenschaft und Kontextueller Informatik ein Datenmodell entwickelt, in dem für den Forschungsprozess bedeutsame Objekte (wie etwa Gebäude, Personen, Transportmittel, Quellen etc.) definiert sind, die mit digitalisierten Quellenfunden angereichert werden können. Dieser mehrstufige Prozess offenbarte ein grundlegendes Problem: Während die grundsätzliche Objekthierarchie gut überschaubar ist, entfaltete sich der Bedarf für eine feinere Objektgranularität mit vertiefender Semantik oft erst bei der Testeingabe von Beispieldaten. Häufig handelt es sich dabei um immanent unscharfe kulturwissenschaftlich-forschungstheoretische Aspekte (wie beispielsweise die vergleichende Betrachtung von ungenau definierten Kalenderdaten und Zeitspannen, wahlweise im Gregorianischen oder im Julianischen Kalender), deren Bedeutsamkeit zwar implizit bekannt ist, die sich aber bei expliziter Betrachtung im üblicherweise exakt spezifizierten informatischen Kanon schwer modellieren lässt.
Aufgrund der Verwendung gebräuchlicher Web-Technologien im Open Source Umfeld kann Omeka nach tiefergehender Betrachtung der Problemstellung mit überschaubarem Aufwand um zusätzliche Funktionen erweitert werden. Dies gilt insbesondere auch für erweiterte bzw. verfeinerte Suchfunktionen, die folglich auf semantischer Ebene weit über die reine Volltextsuche hinausgehen. Auf Basis der strukturiert aufbereiteten Daten und Suchergebnisse können anschließend bestehende und auch neu formulierte Forschungshypothesen einfacher überprüft werden, indem beispielsweise Ergebnisse von Suchanfragen über die Objekte und ihre Beziehungen systematisch ausgewertet werden.
Der Projektbeitrag der Kontextuellen Informatik geht also deutlich über einen reinen „Software-Lieferanten“ hinaus: Im interdisziplinären Dialog mit den Kulturwissenschaften entsteht einerseits eine strukturiertere Sicht des Themenfeldes als sie bislang offensichtlich war. Andererseits entstehen neuartige Eingabe- und Analysewerkzeuge, mit denen die Entwicklung und Überprüfung neuartiger Forschungshypothesen erst möglich wird.