
Quantitative und qualitative Forschung
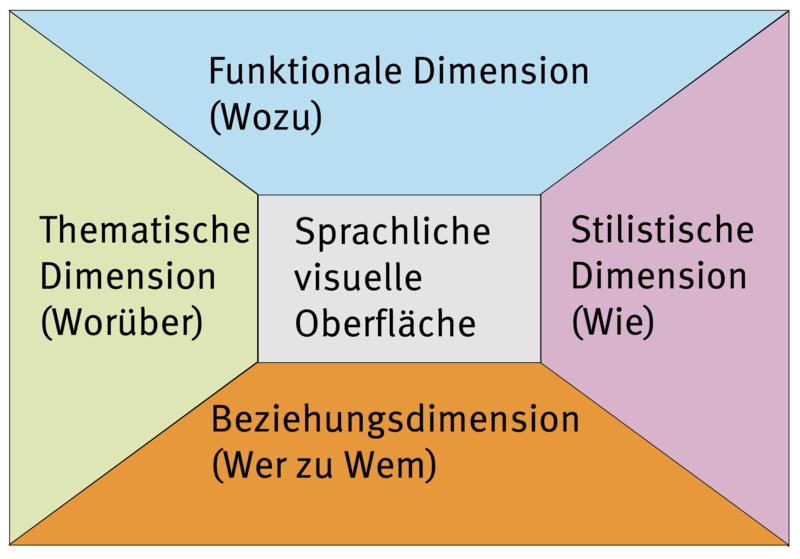

Das im Forschungsvorhaben zugrunde gelegte Analysemodell stellt eine Synthese der in der Textlinguistik der letzten Jahrzehnte vorgestellten mehrdimensionalen Modelle dar. Gleichzeitig wird der Forschungsstand zur historischen Zeitungskommunikation und zur Erbauungsliteratur einbezogen. Ausgehend von Textoberfläche gibt der Sprachgebrauch u.E. Hinweise auf die funktionale, thematische, stilistische und die Beziehungsdimension von Texten.
Im Rahmen der quantitativen Analyse in den Blick genommen werden konkret die musterhaften Ausprägungen der Textoberfläche, die - so die Annahme - auf Gegebenheiten der thematischen, funktionalen, sozialen und stilistischen Dimension hinweisen bzw. diese repräsentieren. Zum großen Teil können die betreffenden Textmuster mit automatisierten Verfahren extrahiert werden. So finden sich z.B. in Andachtsbüchern häufig Wiederholungsstrukturen, die vermutlich der Einprägsamkeit und dem meditativen Charakter des Textes dienen sollen. Solche Wiederholungsstrukturen können durch Wort- oder Phrasenwiederholungen sowie durch grammatische Parallelismen auf der Textoberfläche realisiert sein.
Für die automatische Merkmalsextraktion sind Annotationen bestimmter Texteigenschaften besonders ausschlaggebend: So weisen die Dokumente des DTA bereits TEI-Auszeichnungen von Textgliederungsstrukturen und (ggf.) Binnentextsorten auf. Darüber hinaus stellt das DTA Ausgabeformate bereit, die linguistische Informationen auf Token-Ebene (z.B. Lemma, Wortart und modernisierte Schreibweise) enthalten. Mithilfe dieser Informationen lassen sich bereits viele der zu untersuchenden Merkmale in den Texten automatisch ermitteln. Für weiterführende Analyseschritte, z.B. zu (morpho-)syntaktischen Strukturen, Koreferenzen oder Eigennamen, kann außerdem auf computerlinguistische Verfahren zurückgegriffen werden, die mittlerweile vielfältig frei zur Verfügung stehen (z.B. in CLARINs WebLicht integrierte Syntaxparser). Die Merkmalsextraktion wird häufig vielschichtig sein, d.h. mehrere Informationstypen gleichzeitig in Betracht ziehen und auswerten. Auf die automatische Merkmalsextraktion ebenso wie auf die manuelle Annotation folgt dann die statistische Auswertung der erhobenen Merkmale, wiederum mit automatischen Verfahren.
Die qualitativ orientierte manuelle Annotation berührt Aspekte der funktionalen, stilistischen, thematischen und Beziehungsdimension, die mittels automatischer Verfahren nicht erschlossen werden können. Das Projektteam hat sich für die manuelle Annotation für das browserbasierte Textannotations- und -analysetool CATMA 6.0 entschieden, da es die Möglichkeit bietet, taxonomisch aufgebaute individuelle Tagsets beliebiger Komplexitätsstufen zu erstellen, indem Annotationen problemlos verändert werden können.
CATMA 6.0 erlaubt problemlos den für das Inter-Annotator-Agreement wichtigen Abgleich von Annotationen. Durch die Möglichkeit des XML-Imports und -Exports ist zudem die Nach- und Weiternutzbarkeit der Daten sichergestellt. Die in CATMA annotierten und daraus exportierten Daten werden in eine TEI-P5-Repräsentation überführt und können in dieser Form der weiteren automatischen Bearbeitung zugeführt werden. Sie können somit auch mit den Merkmalen kombiniert werden, die aus der automatischen Datenanalyse gewonnen wurden. Die Annotationen werden dann daraufhin ausgewertet, ob sie Rückschlüsse auf die Wandelprozesse gemäß den Beschreibungsdimensionen und von dort ausgehend bisher in der Forschung etablierte Deutungshypothesen stützen können.
Neben der manuellen Annotation werden die bei der quantitativen Analyse erhobenen Daten qualitativ ausgewertet. Allerdings können auch die Ergebnisse der qualitativen Analyse wieder für Anlass für quantitative Erhebungen sein.
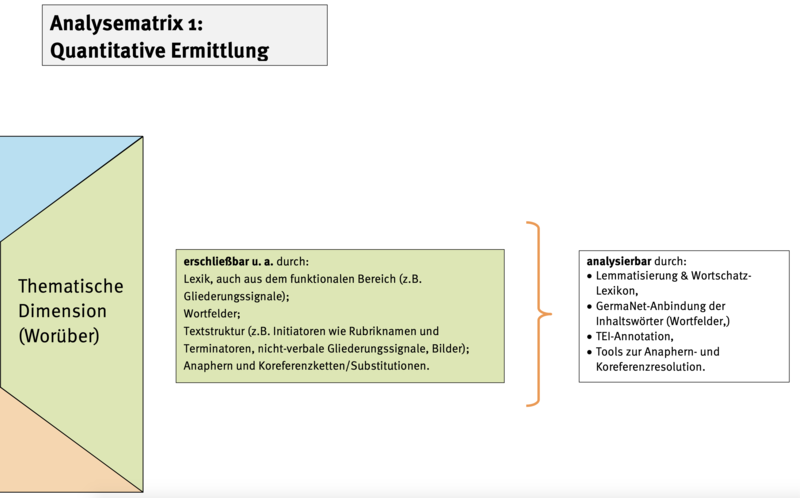
Wir sind der Auffassung, dass sich sprachliche Indikatoren auf der Textoberfläche für die unterschiedlichen Dimensionen teils mittels automatischer Verfahren und computerlinguistischer Software und teils bisher nur mittels manueller Annotation erschließen lassen. Abb. 2 zeigt am Beispiel der funktionalen Dimension, welche sprachlichen Indikatoren ihr zugeordnet werden können und mit welchen automatischen Verfahren diese bearbeitet werden können.
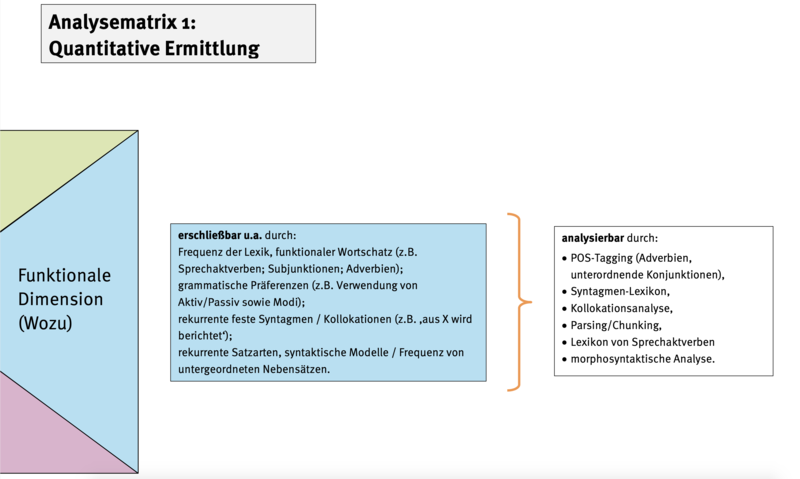
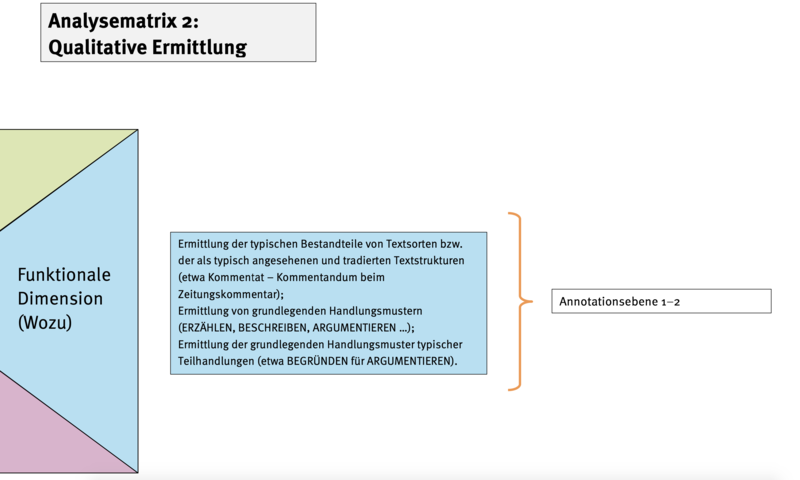
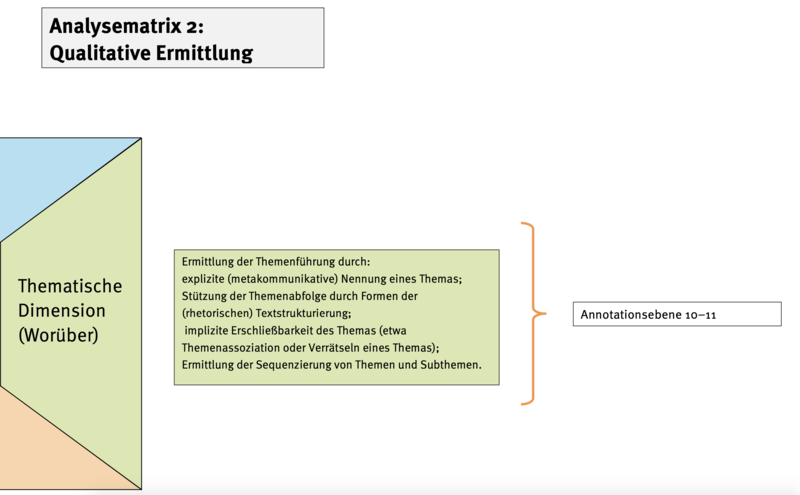
Abb. 3 zeigt hingegen die Aspekte der funktionalen Dimension die nur mittels manueller Annotation bearbeitet werden können. Auf den nachfolgenden Abb. finden sich die übrigen Dimensionen und ihre jeweilige Bearbeitung.
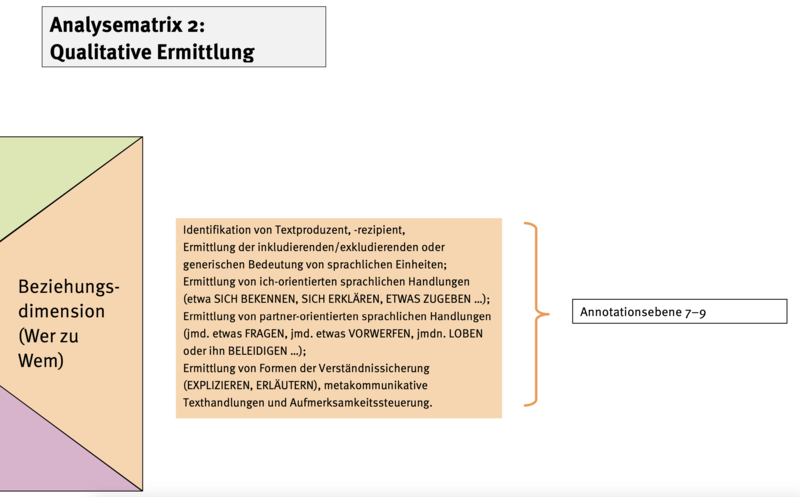
Zum Vorgehen in den übrigen Analysedimensionen auf quantitativer und qualitativer Ebene



Zur Auswertung der Ergebnisse
Die Ergebnisse der statistischen Auswertung sollen in Rückbindung an die Quellen interpretiert und qualifiziert werden; ebenso sollen die Ergebnisse der manuellen Annotation zur automatischen Merkmalsextraktion genutzt werden. Diese Verzahnung von quantitativer und qualitativer Analyse wird in einer Pilotierungsphase erprobt. Wir gehen prinzipiell davon aus, dass durch die automatische Textanalyse andere Aspekte des Textmusterwandels in den Blick geraten (z.B. zeitübergreifende Wandeltendenzen) als durch eine manuelle Annotation, die Ergebnisse aber aufeinander bezogen werden können.
Erste Ergebnisse und die zugrundeliegenden Tagsets sind auf folgender Unterseite einsehbar: Tagsets und manuelle Annotationen.
Kondensat des Vorhabens im DHd-Poster
Das folgende Poster, das im Rahmen der im März 2020 abgehaltenen DHd-Jahrestagung "Spielräume" erarbeitet wurde, gibt das geschilderte Projektvorhaben in kondensierter und exemplarischer Form wieder.
